This is the last homework of the “Corona Sabbatical weeks”. We will resume our classes soon. This is a good chance to get back on track. Please use the template to answer these questions, and send the result to andres.aravena+cmb@istanbul.edu.tr.
Codon counting
One way to detect if a gene was shared between bacteria by horizontal transfer is to look at the codon usage frequency and codon adaptation index. Today we are going to do the first part.
Write a function that takes a DNA sequence (in this case it will be a gene) and returns a vector with the number of times each codon appears on the gene. The vector’s names should be the codon.
There are some functions that you may like to useMore lego pieces!
. One is paste0(), that takes two or more
values and returns a single text with all the valued pasted together.
For example, if the vector gene is
c("g", "a", "t", "t", "a", "c"), and you use
paste0(gene[1], gene[2], gene[3]), you will get the text
"gat".
The other function that you may want to use is
tolower(). It takes a single text and returns the same text
with all letters changed to lower case. For example, if you use
tolower("TAC"), you will get "tac" in
return.
We are going to focus only in counting the codons. To make things easier, we have already part of the code prepared for us. Please fill the missing parts.
codon_count <- function(gene) {
answer <- rep(0, 64)
names(answer) <- c("aaa", "aac", "aag", "aat", "aca", "acc", "acg", "act",
"aga", "agc", "agg", "agt", "ata", "atc", "atg", "att", "caa", "cac",
"cag", "cat", "cca", "ccc", "ccg", "cct", "cga", "cgc", "cgg", "cgt",
"cta", "ctc", "ctg", "ctt", "gaa", "gac", "gag", "gat", "gca", "gcc",
"gcg", "gct", "gga", "ggc", "ggg", "ggt", "gta", "gtc", "gtg", "gtt",
"taa", "tac", "tag", "tat", "tca", "tcc", "tcg", "tct", "tga", "tgc",
"tgg", "tgt", "tta", "ttc", "ttg", "ttt")
# write your code here
return(answer)
}You can test your answer with the following code. If everything goes right, you will get the same output.
codon_count(c("g", "t", "g", "a", "a", "a", "a", "a", "g", "a", "t", "g",
"a","c", "a", "a", "t", "c", "t", "a", "t", "c", "g", "t", "a", "c", "t",
"c", "g", "c", "a", "c", "t", "t", "t", "c", "c", "c", "t", "g", "g",
"t", "t", "c", "t", "g", "g", "t", "c", "g", "c", "t", "c", "c", "c",
"a", "t", "g", "g", "c", "a", "g", "c", "a", "c", "a", "g", "g", "c"))aaa aac aag aat aca acc acg act aga agc agg agt ata atc atg att caa cac cag cat
1 0 1 0 2 0 0 2 0 1 0 0 0 1 1 0 0 0 0 1
cca ccc ccg cct cga cgc cgg cgt cta ctc ctg ctt gaa gac gag gat gca gcc gcg gct
0 0 0 1 0 2 0 1 0 0 0 0 0 0 0 0 0 0 0 0
gga ggc ggg ggt gta gtc gtg gtt taa tac tag tat tca tcc tcg tct tga tgc tgg tgt
0 2 0 2 0 0 1 0 0 0 0 1 0 1 0 1 0 0 0 0
tta ttc ttg ttt
0 1 0 0 codon_count(c("C", "G", "G", "A", "A", "A", "T", "T", "A", "C", "G", "T",
"C","T", "A", "G", "T", "C", "C", "C", "G", "T", "C", "A", "G", "T", "A",
"A", "A", "A", "T", "T", "A", "C", "A", "G", "A", "T", "A", "G", "G",
"C", "G", "A", "T", "C", "G", "T", "G", "A", "T", "A", "A", "T", "C",
"G", "T", "G", "G", "C", "T", "A", "T", "T", "A", "C", "T", "G", "G"))aaa aac aag aat aca acc acg act aga agc agg agt ata atc atg att caa cac cag cat
2 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0
cca ccc ccg cct cga cgc cgg cgt cta ctc ctg ctt gaa gac gag gat gca gcc gcg gct
0 0 1 0 0 0 1 3 1 0 0 0 0 0 0 2 0 0 0 0
gga ggc ggg ggt gta gtc gtg gtt taa tac tag tat tca tcc tcg tct tga tgc tgg tgt
0 2 0 0 1 1 0 0 0 1 0 1 1 0 0 0 0 0 1 0
tta ttc ttg ttt
2 0 0 0 Window GC-skew
In Homework 5 we learned how to calculate GC-skew for a list of genes, and how to calculate GC-content in a genome region, that is, in a “window”. Here we want to combine both ideas, and get GC-skew for a window.
It is probably a good idea to talk with your classmates and get good working versions of the answers to Homework 5. Remember that a goal of this course is to learn how to work in teams and collaborate with your peers. This is how good scientists work.
Please write a function called window_gc_skew that takes
inputs genome, position,
window_size and returns the GC skew for the letters in the
genome regions starting from position, for the length of
window_size.
window_gc_skew <- function(genome, position, window_size) {
nC <- 0
nG <- 0
## for each index value, starting from position, count nG and nC
if(nG+nC==0) {
return(0)
} else {
return((nG-nC)/(nG+nC))
}
}Notice that this function returns a single number. You can test your function with the following code.
library(seqinr)
ecoli <- read.fasta("NC_000913.fna")
window_gc_skew(ecoli[[1]], 10, 1000)[1] 0.00589391window_gc_skew(ecoli[[1]], 2345678, 2000)[1] -0.01117318Using window_gc_skew() in many places
Following again the idea from Homework 5, we want to apply the
function window_gc_skew() through all the genome. As
before, the result depends on the genome and the window size. Please
write a function that takes as inputs genome and
window_size, and returns a data frame with the
position and GC-content of each window.
many_places_gc_skew <- function(genome, window_size) {
genome_position <- seq(from=1, to=length(genome)-window_size, by=window_size)
skew <- rep(NA, length(positions))
# for each index in genome_position calculate skew using window_gc_skew()
answer <- data.frame(genome_position, skew)
return(answer)
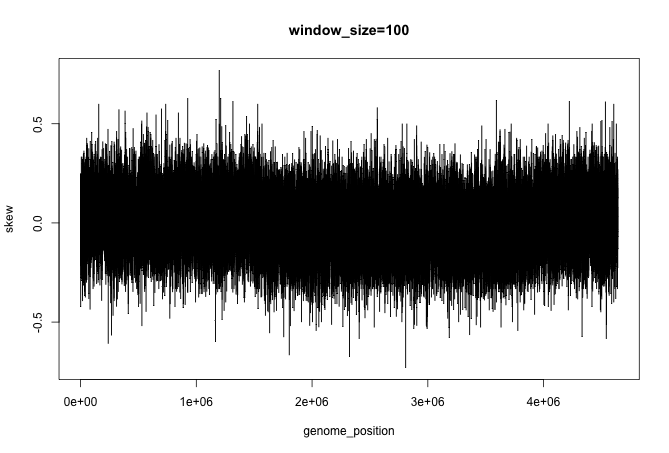
}Since the function returns a large data frame, it is not practical to print the numbers. Instead, we can plot them. The following code will help you see if your function is correct. It is not very fast, so do not worry if this part takes several minutes to finish.
library(seqinr)
ecoli <- read.fasta("NC_000913.fna")
plot(many_places_gc_skew(ecoli[[1]], 10000), main="window_size=10000", type="l")
plot(many_places_gc_skew(ecoli[[1]], 1000), main="window_size=1000", type="l")
plot(many_places_gc_skew(ecoli[[1]], 100), main="window_size=100", type="l")