The best way is to download the data file and save it into a local folder
Then you can read it as much as you like
November 15th, 2018
The best way is to download the data file and save it into a local folder
Then you can read it as much as you like
If you want to load data directly from the web use a code like this We read data with a code chunk like this
```{r cache=TRUE}
URL <- “http://anaraven.bitbucket.io/static/2018/cmb1/”
survey <-read.table(paste0(URL,“survey1-tidy.txt”),header=TRUE)
survey2 <-read.table(paste0(URL,“survey2.txt”), header=TRUE)
```
Please include the cache=TRUE chunk option
It will be faster and nicer on the server
The commands in this page produce the plots of the following page
plot(survey$height_cm, main="1") plot(survey$height_cm, main="2", col="red") plot(survey$height_cm, main="3", cex=2) plot(survey$height_cm, main="4", cex=0.5) plot(survey$height_cm, main="5", pch=16) plot(survey$height_cm, main="6", pch=".")

The commands in this page produce the plots of the following page
plot(survey$height_cm, main="1", type = "l") plot(survey$height_cm, main="2", type = "o") plot(survey$height_cm, main="3", type = "b") plot(survey$height_cm, main="4", type = "p") plot(survey$height_cm, main="5", xlim=c(1,20)) plot(survey$height_cm, main="6", xlim=c(30,51))

plot(survey$height_cm, ylim=c(0,200)) points(survey$weight_kg, pch=2)
plot(survey$height_cm, type="l", ylim=c(0,200)) lines(survey$weight_kg, col="red")

plot(survey$height_cm, col=survey$Gender)
legend("topleft", legend=c("Female", "Male"), fill=c(1,2))

plot(survey$height_cm) abline(h=mean(survey$height_cm), col="red", lwd=5)

This command adds a straight line in a specific position
abline(h=1) adds a horizontal line in 1abline(v=2) adds a vertical line in 2abline(a=3, b=4) adds an \(y=a +b\cdot x\) line
a is the intercept when \(x=0\)b is the slopeplot(survey$height_cm) abline(v=20, col="blue") abline(a=160, b=0.5)

plot(survey$height_cm, survey$weight_kg)

plot(survey$height_cm, survey$hand_span_cm)

Instead of
plot(survey$height_cm, survey$weight_kg)
we can write
plot(survey$weight_kg ~ survey$height_cm)
or even
plot(weight_kg ~ height_cm, data = survey)
plot(height_cm ~ hand_span_cm, data = survey)
plot(height_cm ~ hand_span_cm, data = survey,
subset = Gender=="Female")
plot(height_cm ~ hand_span_cm, data = survey,
subset = Gender=="Male")
It is easier to specify the data.frame and which values to plot
plot(height_cm ~ weight_kg, data=survey)

survey$handness <- as.factor(survey$handness) plot(Gender ~ handness, data=survey)

plot(Gender ~ weight_kg, data=survey)

plot(weight_kg ~ Gender, data=survey)

Plotting a numeric value depending on a factor results in a boxplot
It is a graphical version of summary().

plot(weight_kg ~ Gender, data=survey, boxwex=0.3,
notch=TRUE, col="grey")

plot(survey)
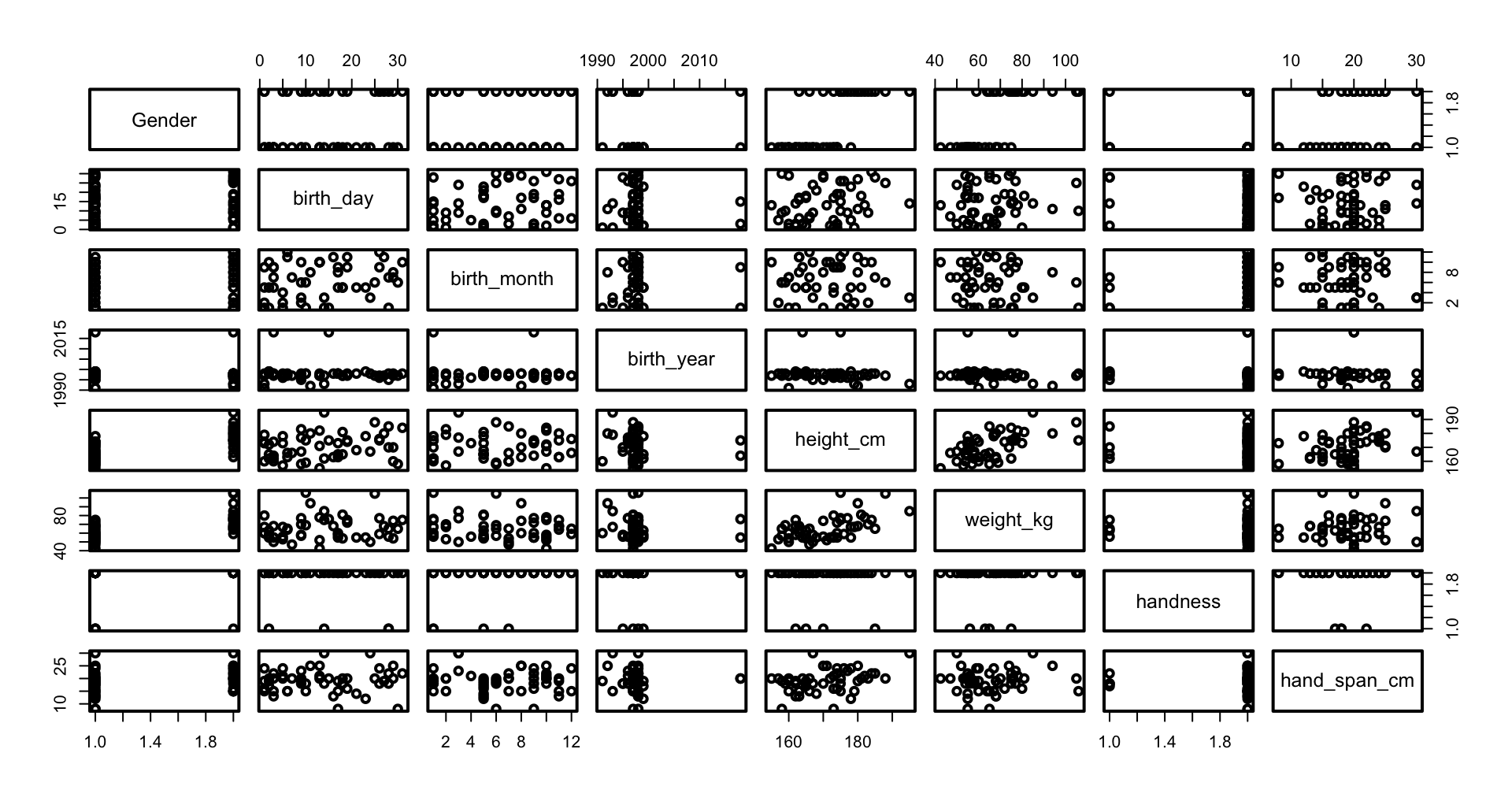
plot() can be used with one or two vectors, or with a formulaplot(y ~ x) looks like plot(x, y)plot(y~x, data=dframe) is better than plot(dframe$x, dframe$y)The figure type depends on the data type of the vector
points() or lines()barplot()boxplot()pairs()plot() command defines the ranges, labels and titlepoints(), lines()text()segment(), arrows(),rect(), polygon() xspline()legend()Learn more on the help page of each command
Colors can be specified in several ways:
Write an R command to assign this list to the variable x, and show its content
x <- list(weight=c(5.58, 6.11, 4.61, 4.53, 5.14, 4.17,
3.59, 3.83, 4.89, 4.69, 5.12, 5.50, 5.29, 6.15, 5.26),
group=factor(rep(c("ctrl", "trt1", "trt2"), c(5,5,5))))
x
x <- list(weight=c(5.58, 6.11, 4.61, 4.53, 5.14, 4.17,
3.59, 3.83, 4.89, 4.69, 5.12, 5.50, 5.29, 6.15, 5.26),
group=factor(c("ctr1", "ctr1", "ctr1", "ctr1", "ctr1",
"trt1", "trt1", "trt1", "trt1", "trt1",
"trt2", "trt2", "trt2", "trt2", "trt2")))
Write the code to print all weights except the third one
x$weight[-3]
x[[1]][-3]
weird answer (people?)
people$weight[-3]
Write the code to print the mean of weight only for the cases where group is equal to "trt1"
mean(x$weight[x$group == "trt1"])
a <- x$weight[x$group=="trt1"] mean(a)
weird answers
mean(x$weight[6:10])
mean(weight[c(-1,-2,-3,-4,-5,-11,-12,-13,-14,-15)])
x$weight[x$group=="trt1"]
Write the code to find the group of the element whose weight is equal to the median of all weight
x$group[x$weight==median(x$weight)]
a <- median(x$weight) x$group[a==x$weight]
Write the command to show the column names of world.
colnames(world)
weird answer
colnames<-("population", "contenient", "life_exp")
Write the command to find how many lines are there in the wolrd data frame
nrow(world)
weird answers
dim(world) summary(world)
Write the command to show the first 5 lines of world.
world[1:5, ]
M <- world[1:5, ] M
weird
list(world[1, ], world[2, ], world[3, ], world[4, ], world[5, ])
Write the command to show the data corresponding to Turkey
world["Turkey",]
weird
world[row.names="Turkey"]
Write the command to count the number of times that each value appears in the continent column
table(world$continent)
weird
ncol(world$continent) colnames(contenient) length(world$continent)
Which countries have population greater than 200 million people?
world[world$population>2e8, ]
better
rownames(world)[(world$population>200000000)]
Write the command to create a data frame called Africa with all the rows of world where continent=='Africa'. Show the result of summary(Africa)
Africa <- world[world$continent=="Africa",] summary(Africa)
weird
data.frame(world$state.area >20000000)
Show the value of the maximum population.
max(Africa$population)
weird
summary(world[world$continent== "Africa" , ])
Show the row of the country which population is the maximum.
Africa[which.max(Africa$population),]
Alternative
Africa[Africa$population==max(Africa$population),]
Which is the life expectancy of the African country with the smallest population? Show the life_exp column of the country which population is the minimum.
Africa$life_exp[which.min(Africa$population)]
Alternatives:
Africa[Africa$population==min(Africa$population), "life_exp"]
world$life_exp[which.max(world$population[world$continent=="Africa"])]
Alternatives
z <- min(Africa$population) Africa$life_exp[z==Africa$population]
min <- which.min(Africa$population) Africa[min,"life_exp"]
a <- world[world$continent=="Africa", ] a[min(a$population)==a, "life_exp"]
weird answers
min(life_expectancy$Africa)
min(world$population)